This post explores the Google Sheets REGEX formulas with a series of examples to illustrate how they work.
Regular expressions, or REGEX for short, are tools for solving problems with text strings. They work by matching patterns.
You use REGEX to solve problems like finding names or telephone numbers in data, validating email addresses, extracting URLs, renaming filenames containing the word “Application” etc.
They have a reputation for being hard, but once you learn a few basic rules and understand how they work you can use them effectively.
There are three Google Sheets REGEX formulas: REGEXMATCH, REGEXEXTRACT, and REGEXREPLACE.
Each has a specific job:
• REGEXMATCH will confirm whether it finds the pattern in the text.
• REGEXEXTRACT will extract text that matches the pattern.
• REGEXREPLACE will replace text that matches the pattern.
Let’s understand them with a series of examples.
 💡 Learn more
💡 Learn moreLearn more about REGEX formulas in my latest course: The Google Sheets REGEX Formula Cookbook
Table Of Contents
- Example 1: Google Sheets REGEXMATCH
- Example 2: Google Sheets REGEXEXTRACT
- Example 3: Google Sheets REGEXREPLACE
- Example 4: Use REGEXEXTRACT And VALUE To Extract Numbers From Text
- Example 5: Check Telephone Numbers With REGEXMATCH
- Example 6: Reorder Name Strings With REGEXREPLACE
- SOLUTION From Example 1 Question
- Learn More
Example 1: Google Sheets REGEX Formula REGEXMATCH
The REGEXMATCH function returns a TRUE if it matches the pattern you provide anywhere in the text and FALSE if there are no matches in the text.
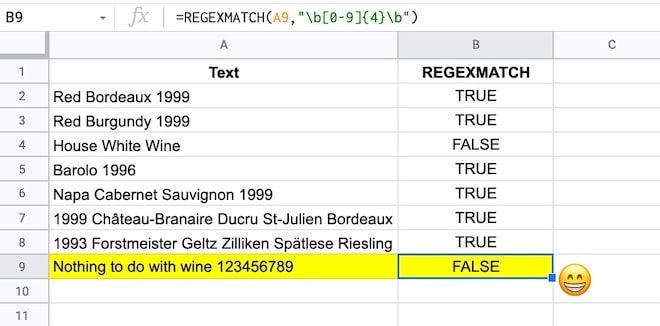
For example, suppose we have this dataset of vintage wines, where each row has a mix of text and/or numbers:
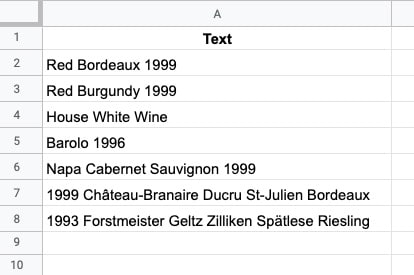
Let’s create a simple REGEXMATCH to test whether a cell contains a number, i.e. the year vintage is given.
In cell A2, add this formula:
=REGEXMATCH(A2,"[0-9]")This will give a TRUE output if it finds a number in the string, or FALSE if there are no numbers.
[0-9]+matches any number from 0 to 9 in the input string.
So, provided there is one number in the input string, this pattern will give us a match:
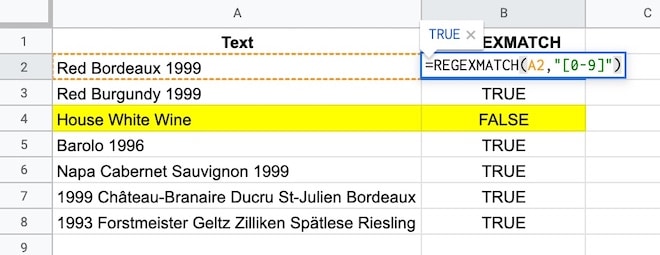
See how the text without any numbers “House white wine” gives a FALSE output because there is no match.
Important Note
This pattern matches a single number. It doesn’t care what else might be in the cell.
For example, it returns TRUE for a meaningless string containing numbers, which is probably not the behavior you’re looking for in this case.
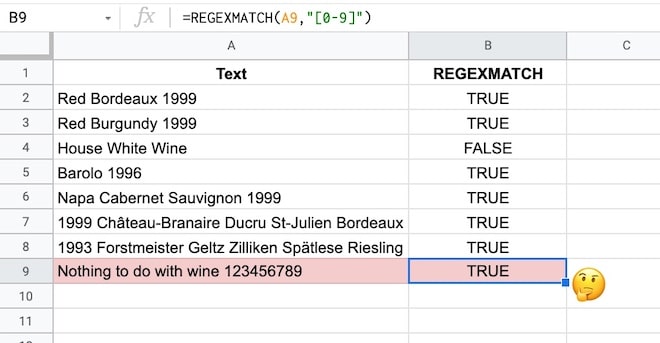
By the end of this tutorial, you’ll understand enough to know how to fix this yourself.
(For the solution, see the formula at the end of this tutorial.)
Example 2: Google Sheets REGEX Formula REGEXEXTRACT
Using the same wine dataset as above, we want to create a new column in our dataset with the vintages, i.e. a column with the year only.
This is a perfect example of when to use a Google Sheets REGEX formula. We’ll create a regular expression pattern to match any numbers and then use REGEXEXTRACT to extract them.
As with everything in spreadsheets, there are multiple REGEX patterns that could solve this.
We saw this pattern above:
[0-9]but we can also use the named character class for digits:
\dThis matches any digits (i.e. numbers 0 to 9).
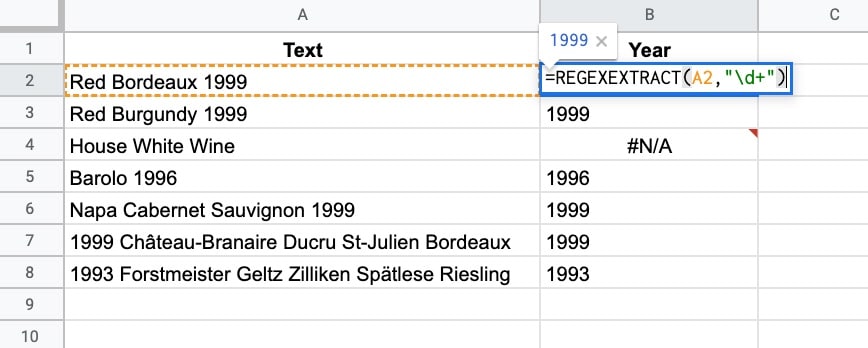
So the REGEXEXTRACT formula to extract the year looks like this:
=REGEXEXTRACT(A2,"[0-9]+")or
=REGEXEXTRACT(A2,"\d+")Then
+means get one or more.
Both formulas return a result of “1999” because the text in A2 is “Red Bordeaux 1999”.
If no numbers are found, the formula returns a #N/A error.
Two Important Notes
Note 1:
The REGEX formulas require text inputs and they give you text outputs back. So the 1999 output above is formatted as text. To convert to a number you need to wrap the result with a VALUE function. See Example 4 below for more details.
Note 2:
If there were more numbers in the text string e.g. “Red Bordeaux 1999 or 2001” only 1999 is returned by the REGEXEXTRACT formula because it doesn’t match the space or letters between the numbers.
It only matches the numbers, so it matches the first number it sees, then keeps matching numbers until it hits the first non-number where it stops matching, i.e. the space at the end of 1999.
Example 3: Google Sheets REGEX Formula REGEXREPLACE
The REGEXREPLACE will replace all sets of numbers in the text with a new value, for example, this formula:
=REGEXREPLACE(A2,"\d+","2021")will replace 1999 in the sentence “Red Bordeaux 1999” with “2021” and return the answer: Red Bordeaux 2021.
Important Note
The REGEXREPLACE function replaces ALL sets of numbers in the text, unlike the REGEXEXTRACT which just extracts the first pattern it matches.
Example 4: Use REGEXEXTRACT And VALUE To Extract Numbers From Text
Consider this data about a supertanker ship:

Is it possible to extract those numbers with a REGEX formula, even though they’re formatted differently?
You bet!
This formula will extract numbers with or without thousand separators and/or decimal places:
=REGEXEXTRACT(A2,"[\d,.]+")The REGEX pattern
[\d,.]+means match any digits, commas, or periods and extract them.
So the REGEXEXTRACT formula matches the first digit it finds then keeps going with the match provided the next character is either another digit or a comma or a period, When it reaches something else, like a space or a letter, the match breaks, and the extract is completed.
We’re not quite done yet though.
Using The VALUE Function To Convert The Output To Numbers
The output of the REGEXEXTRACT formula is a string, not a number.
So we need to convert the output to a number by wrapping the result with the VALUE function like this:
=VALUE(REGEXEXTRACT(A2,"[\d,.]+"))The formula above is not foolproof, however.
Improving The Pattern Match
If the text string has a period or comma before the first digit then this will be extracted as the match.
For example, if the input text string was: “The ship is huge. It’s 630,962 tonnes full load.” then the REGEXEXTRACT formula from above will extract the first period only.
It matches the period after “huge” and then stops the match because of the space character that follows.
How do we modify the formula to ensure the extract begins with a number?
Well, we change the REGEX to match a number first, before anything else, like this:
=REGEXEXTRACT(A2,"\d[\d,.]*")Here the REGEX matches on a digit first, before looking for more digits, commas, or periods.
If you’re eagle-eyed you’ll notice that the plus + has changed to a star * after the square bracket. This means zero or more of the characters in the square brackets, to account for a situation where there is a single-digit number that we want to match.
The REGEX pattern
\d[\d,.]*matches a digit, followed by zero or more characters that are digits, commas, or periods.
Now the result of the formula extraction is 630,962, which is the correct answer.
Remember, the output of the REGEXEXTRACT formula is a string, so you’ll need to wrap it with the VALUE function to convert it to a number, e.g.
=VALUE(REGEXEXTRACT(A2,"\d[\d,.]*"))Example 5: Check Telephone Numbers With REGEXMATCH
For this example, I’m going to consider US phone numbers with dashes between the sections, i.e. numbers of this format: XXX-XXX-XXXX
It’s 3 digits, then a dash, 3 digits, dash, then 4 digits.
By the end of this tutorial, you’ll have enough information to modify the example to other regions of the world.
Here’s the data:
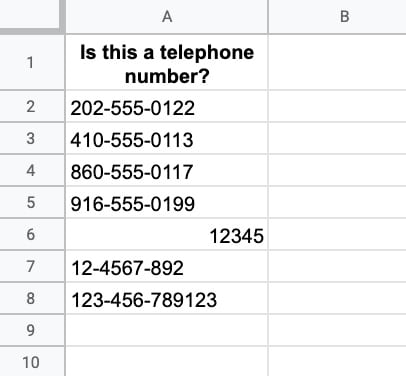
Let’s build a REGEX formula to check whether the string in column A is a valid US phone number.
Using what we learned above, we know that the expression
\dmatches digits. So our first attempt is this formula:
Step 1:
=REGEXMATCH(A2,"\d\d\d-\d\d\d-\d\d\d\d")This matches 3 digits, then a dash, 3 digits, dash, then 4 digits and it works ok. It shows TRUE when it matches a telephone number and FALSE otherwise.
But it’s verbose. We can simplify it by using a quantifier clause.
Step 2:
=REGEXMATCH(A2,"\d{3}-\d{3}-\d{4}")The {3} means match exactly 3 of the preceding pattern, i.e. match exactly 3 digits.
This works great, except it still matches the final number on row 8. It matches the 3-3-4 and doesn’t care about the extra digits that come at the end.
But we know this isn’t a valid phone number, so how do we get it to stop after the 4 digits and discount anything with more than 4 digits in the final set?
Word Boundaries
We wrap the expression with a special expression called a word boundary, denoted by
\bbefore and after the main expression.
Technically, this matches a “zero-width nothing”. What that means is that it marks a boundary between a word character (e.g. letter or digit or _) and a non-word character. So it will match the digits up to 4 and then look for a boundary. A fifth digit will break the match, but a space won’t because it defines a boundary.
Our new expression looks like this, with a \b at the beginning and end.
Step 3:
=REGEXMATCH(A2,"\b\d{3}-\d{3}-\d{4}\b")The final thing we might do is to wrap this with an IFERROR function to handle number inputs like row 6 above that cause an error output (since the REGEX formulas only work with text strings).
Step 4:
=IFERROR(REGEXMATCH(A2,"\b\d{3}-\d{3}-\d{4}\b"),FALSE)
Example 6: Reorder Name Strings With REGEXREPLACE
In this example, we’re looking at the REGEXREPLACE function and a key concept in regular expressions: capturing groups.
Suppose we have a list of names in this format: “Surname, First Name” and we want to switch the order to “First Name Surname”.
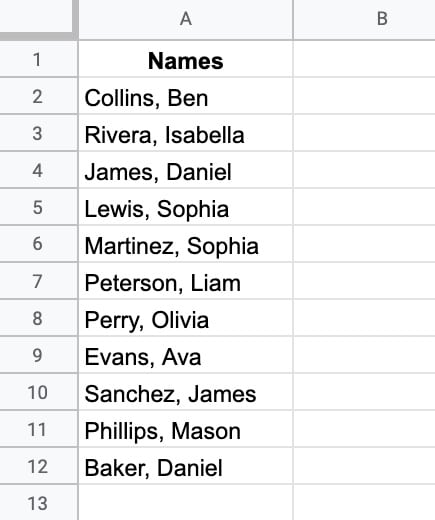
Here’s the formula to switch the order of the names:
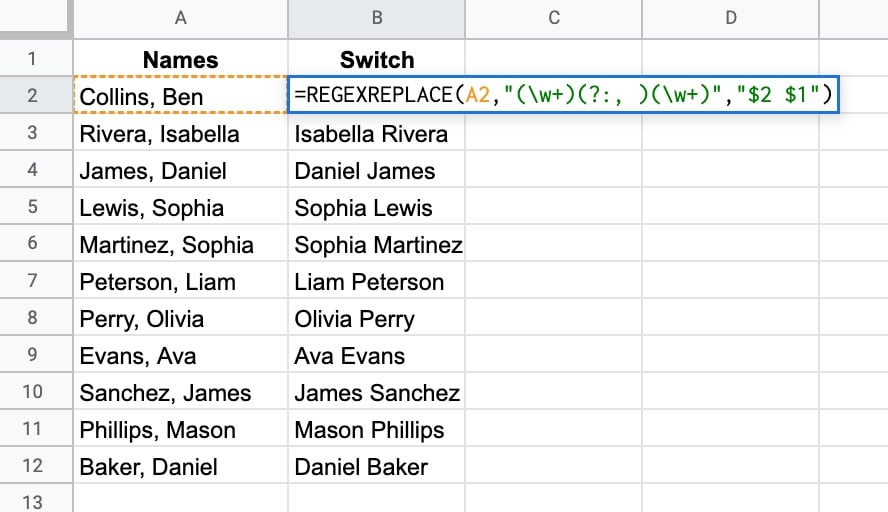
=REGEXREPLACE(A2,"(\w+)(?:, )(\w+)","$2 $1")Let’s break this down:
REGEXREPLACE finds all substrings that match the pattern and replaces them with the value given. It takes 3 arguments: 1) the input text, 2) the pattern to match, and 3) the replacement value.
Let’s look at each in turn:
Input text
Surname, First name e.g. Collins, Ben
Matching pattern
(\w+)(?:, )(\w+)\w+matches word characters.
(\w+)creates a numbered capturing group. It matches the first word up to the comma.
(?:opens a non-capturing group, which essentially means match but don’t capture the text in this group.
(?:, )is the non-capturing group that matches a comma and space but doesn’t capture them.
(\w+)creates a second numbered capturing group. It matches the second word after the comma and space.
Replacement Value
$2 $1Now, this is where it gets interesting!
Our matching pattern captured each of the names as a numbered group, which we’re now able to refer to with
$1or
$2The group
$1captured the surname and group
$2captured the first name.
To reverse the names, we put group
$2first, then
$1The output looks like this:
SOLUTION From Example 1
Modify the REGEXMATCH formula to be:
=REGEXMATCH(A2,"\b[0-9]{4}\b")It uses a quantifier
{4}and word boundaries
\bto only match 4-digit numbers (see example 5 for more information on quantifiers and word boundaries).
Learn More
The Google Sheets REGEX Formula Cookbook
There are hundreds of more REGEX examples in my Google Sheets REGEX Formula Cookbook course.
💡 Learn moreLearn more about REGEX formulas in my latest course: The Google Sheets REGEX Formula Cookbook
Resources
For the full list of allowed syntax, check the re2 syntax page.
Great post. Looking forward to the Cookbook.
Thanks, Giovanni. Coming soon… I finished the last video earlier today 🙂
Great content, Ben. Really appreciate your work.
Can you do another post on how we can extract all the matches (for example: All emails in a string where the number of emails are not fixed and there is not a specific type of delimiter) with REGEX.
Thank you.
Hello Ben,
Thank you so much for your valuable content.
I am really enjoying learning more about the formulas with your help.
I have one question.
Suppose I have a line of code and a website link and I want to extract this website link from the code.
How can I do that?
Ben, good stuff! I have a email address in C2 and want to obscure it with asterisks. The pattern I found is /(?!^).(?=[^@]+@)/
In my Google sheet, I have this in cell C3 (where I want the obscured address:
REGEXREPLACE(c2,”/(?!^).(?=[^@]+@)/”,”*”)
Not working… What am I missing?
Hi Ben,
Did you notice that the regexextract function now seems to work with grouping?
This allows the following function definition:
=regexextract ( lower ( color ),”#?” & rept ( “(” & rept ( “[0-9a-fA-F]”, quotient ( len ( color ), 3 ) ) & “)”, 3 ) )
to handle a color input like #badbed and return { “ba”, “db”, “ed” } and if color is set to “#1ab”, it will return { “1”, “a”, “b” }.
In other words, regexextract now returns a vector when you use grouping (at least in my version of sheets, the one with named functions but without map/reduce yet)
Great article! Thank you!
Hi Ben,
Thank you for the article.
I have a question. I am trying to use the REGEXREPLACE function to change the format of several dates within text in a cell, e.g., from 12/06/2022 to 2022-12-06. I can create a RegEx expression to accomplish the conversion, but an unfortunate thing happens. All the existing text formatting is lost. Even in text that was unchanged. Is there any way to preserve the text formatting?
Below is an example of the issue.
Cell A1 value:
Date is 12/06/2022 (“Date” and “12/06/2022″ are bold)
Cell B1 Formula
REGEXREPLACE(A1,”(\d{2})/(\d{2})/(\d{4})”,”$3-$1-$2″)
Cell B1 value:
Date is 2022-12-06 (none of the text is bold)
Bonjour,
Très bon article.
Je pourrais ajouter que l’expression
=REGEXREPLACE(A2,”(\w+)(?:, )(\w+)”,”$2 $1″)
peut être remplacée par
=REGEXREPLACE(A2,”(\w+),(\w+)”,”$2 $1″)
qui est un peu plus limpide 😉
Hi Ben
Thank you for your interesting lessons.
I wonder what regex expression you need if you have possibly 2 or more surnames or 2 firstnames?
Thx!
I already found the solution:
([\w ]*\w+)(?:, )(\w+[\w ]*)
I have a question on this subject. How can I modify this query to extract number and letter when data is this:
=REGEXEXTRACT(L2,”(\d+)\s(.*)”)
123 Bell Street, extract would be 123 one column and Bell Street in second column
if the address was 123A Bell Street the query fails how could I extract 123A in one column and Bell Street in the second