Want to build a web scraper in Google Sheets? Turns out, basic web scraping, automatically grabbing data from websites, is possible right in your Google Sheet, without needing to write any code.
You can extract specific information from a website and show it in your Google Sheet using some of Sheets’ special formulas.
For example, recently I needed to find out the authors for a long list of blog posts from a Google Analytics report, to identify the star authors pulling in the page views. It would have been extremely tedious to open each link and manually enter each author’s name. Thankfully, there are some techniques available in Google Sheets to do this for us.
Web Scraper Basic Example
Click here to get your own copy >>
For the purposes of this post, I’m going to demonstrate the technique using posts from the New York Times.
Step 1:
Let’s take a random New York Times article and copy the URL into our spreadsheet, in cell A1:

Step 2:
Navigate to the website, in this example the New York Times:
Note – I know what you’re thinking, wasn’t this supposed to be automated?!? Yes, and it is. But first we need to see how the New York Times labels the author on the webpage, so we can then create a formula to use going forward.
Step 3:
Hover over the author’s byline and right-click to bring up the menu and click "Inspect Element" as shown in the following screenshot:
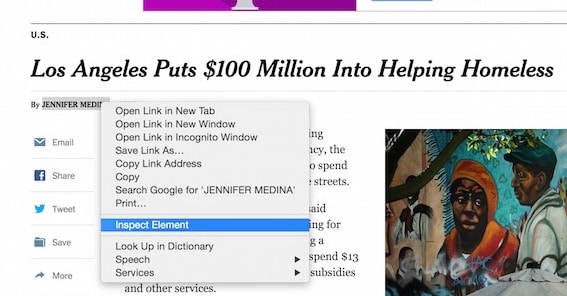
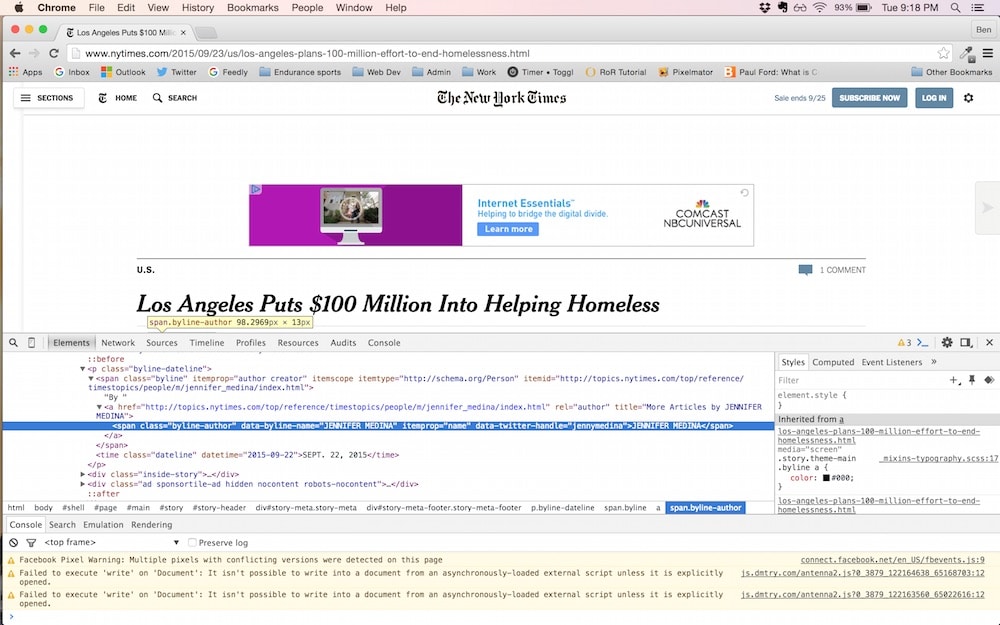
This brings up the developer inspection window where we can inspect the HTML element for the byline:
Step 4:
In the new developer console window, there is one line of HTML code that we’re interested in, and it’s the highlighted one:
<span class="byline-author" data-byline-name="JENNIFER MEDINA" itemprop="name" data-twitter-handle="jennymedina">JENNIFER MEDINA</span>
We’re going to use the IMPORTXML function in Google Sheets, with a second argument (called “xpath-query”) that accesses the specific HTML element above.
The xpath-query, //span[@class='byline-author'], looks for span elements with a class name “byline-author”, and then returns the value of that element, which is the name of our author.
Copy this formula into the cell B1, next to our URL:
=IMPORTXML(A1,"//span[@class='byline-author']")The final output for the New York Times example is as follows:

Web Scraper example with multi-author articles
Consider the following article:
http://www.nytimes.com/2015/09/25/us/pope-francis-congress-speech.html
In this case there are two authors in the byline. The formula in step 4 above still works and will return both the names in separate cells, one under the other:

This is fine for a single-use case but if your data is structured in rows (i.e. a long list of URLs in column A), then you’ll want to adjust the formula to show both the author names on the same row.
To do this, I use an Index formula to limit the request to the first author, so the result exists only on that row. The new formula is:
=INDEX(IMPORTXML(A1,"//span[@class='byline-author']"),1)Notice the second argument is 1, which limits to the first name.
Then in the adjancent cell, C1, I add another formula to collect the second author byline:
=INDEX(IMPORTXML(A1,"//span[@class='byline-author']"),2)This works by using 2 to return the author’s name in the second position of the array returned by the IMPORTXML function.
The result is:

Other media web scraper examples
Other websites use different HTML structures, so the formula has to be slightly modified to find the information by referencing the relevant, specific HTML tag. Again, the best way to do this for a new site is to follow the steps above.
Here are a couple of further examples:
For Business Insider, the author byline is accessed with:
=IMPORTXML(A1,"//li[@class='single-author']")For the Washington Post:
=INDEX(IMPORTXML(A1,"//span[@itemprop='name']"),1)Using IMPORTHTML function to scrape tables on websites
Click here to get your own copy >>
Consider the following Wikipedia page, showing a table of the world’s tallest buildings:
https://en.wikipedia.org/wiki/List_of_tallest_buildings
Although we can simply copy and paste, this can be tedious for large tables and it’s not automatic. By using the IMPORTHTML formula, we can get Google Sheets to do the heavy lifting for us:
=importhtml(A1,"table",2)which gives us the output:
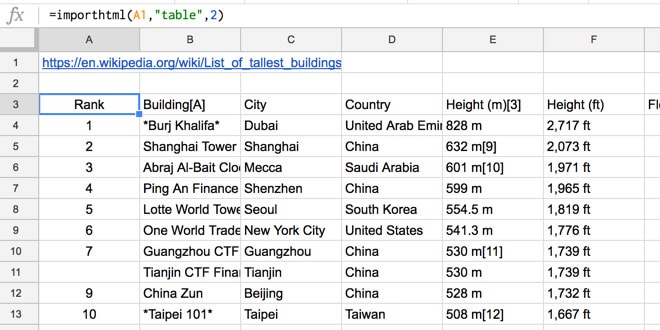
Finding the table number (in this example, 2) involves a bit of trial and error, testing out values starting from 1 until you get your desired output.
Note, this formula also works for lists on web pages, in which case you change the “table” reference in the formula to “list”.
Further reading
For more advanced examples, check out:
How to import popular social media network statistics into Google Sheets
Other IMPORT formulas:
If you’re interested in expanding this technique then you’ll want to check out these other Google Sheet formulas:
IMPORTDATA – imports data at a given url in .csv or .tsv format
IMPORTFEED – imports an RSS or ATOM feed
IMPORTRANGE – imports a range of cells from a specified spreadsheet.
Is there a way to grab data that is protected by a password, such as the total subscriber count in my email newsletter? What is the syntax for that?
Hey Cindi!
Unfortunately these IMPORT formulas cannot work with data behind a password wall. What email service provider are you using? It’s relatively easy to connect to the MailChimp API (haven’t tried any others) and extract all sorts of email subscriber data that way. I’ll be publishing a post on this soon.
Cheers,
Ben
Hi Ben – this doesn’t seem to be working form Trying to scrap using your formula but I’m getting ‘imported content is empty’.
Has Business Insider changed their code?
Thanks,
Hey Dave,
Tested it just now with this url: http://www.businessinsider.com/what-to-expect-from-apple-q2-earnings-2017-5 and it still works for me. It extracted the author name Kif Leswing. Check your formula is pointing to the right cell with the url in, e.g. if the url is in A1, put A1 into the IMPORT formula. Article originally had A19 in the formula, which may have been misleading.
Cheers,
Ben
Hi Ben. I’m trying to use part of your post to create a certain formula but am having trouble. Maybe you could help. I’d like to create a Google Sheets formula to to pull live data from Yahoo Finance to get certain stock information. The function “Googlefinance” doesn’t display everything I need and it also presents data that is at least 20 minutes delayed from the real time. Anyway, I want my formula to display the YTD, 1-month, 3-month, 6-month, 1-year, 3-year, 5-year, 10-year, and max return on investment percents. I’d like the formula to display these results in one column and look up the data from Yahoo Finance based on the stock symbols I’d manually enter into another column. An example would be I’d manually type in “ZROZ” in cell A1 and the formula would yield cells B1:J1 with all the live data from Yahoo Finance. The website is https:// finance.yahoo. com/quote/ZROZ/ performance?p=ZROZ
Any ideas??
Ben, hello.
how to take one cell from the table and direct it to the site, for example, A1 is the product’s line of knowledge, A2 is the price of the product.?
Hi Ben,
If I need to log in to a bunch of websites (because of subscriptions) and then download content based on a criterion I am interested in, can I do that with the Mailchimp API and if so, how can I do that?
The steps I envision are as follows:
1. Open google sheets
2. Create list of websites along with usernames and password columns that I want to scrape my content from
3. Run the formulas (with some sort of execution command, I guess), ie., perform import
4. Save all the content to my Google Drive
5. Run my criterion on these say, PDF documents, ZIP files, etc., or summary table of information and then download “detail”
6. Save Detail content on to another location on G-drive.
Thanks in advance,
Hi Ben,
Nice stuff!
Did you ever post anything on loggin on to websites with an ID and PW?
Wondering now that it’s 2020 is this still the case? Looking to get data off a site that’s password protected. Wonder if it’s possible if I log in first then run the command?
Hi Ben,
I like to ask your help. I used IMPORTHTML on this website – https://www.bursamalaysia.com/market_information/equities_prices?keyword=&top_stock=&board=MAIN-MKT&alphabetical=§or=&sub_sector=&sort_by=short_name&sort_dir=asc&page=1&per_page=50.
But I get “Could not fetch URL…” message. Please advice.
Hey ben,
How do you manually collect raw data and put into googles sheets easily?
Hey Ben,
How would you go about grabbing the “Client Buys” price from this site: https://www.tdcanadatrust.com/customer-service/todays-rates/rates.jsp
I’ve tried several different things with no luck.
Hey Dave,
Unfortunately I’ve not been able to grab the client buys data either. I think the problem is that the page content is dynamically generated (it’s a Java Server Page or .jsp which means the content is programmatically created) so the import formulas can’t parse this data.
I’ll let you know if I get anything working!
Cheers,
Ben
Any news about this topic?
Can we grab data from Google.com and show all the URL in one column against a query for e.g. I search for “Usman Farooq”
I return a #N/A when trying this with instagram. I’m trying to import the # of posts for a given hashtag. As an example, the following URL of https://www.instagram.com/explore/tags/fitness/?hl=en using =IMPORTXML(A2,”//span[@class=’_bkw5z’]”) where A2 is the URL returns #N/A. Any ideas?
Hi Rich,
Have a look at this comment thread on my other IMPORT article, starts with this comment: https://www.benlcollins.com/spreadsheets/import-social-media-statistics/#comment-31914
and the eventual solution is this comment: https://www.benlcollins.com/spreadsheets/import-social-media-statistics/#comment-33035
Let me know if that works for you…
Cheers,
Ben
Thanks Ben! I will check it out after work later this evening and let you know my results.
sheet not working, cs class changed, must be
class=”css-1baulvz”
Hello Guys,
I don’t know is this specific for the region (europe) or google has changed something (post is 2-year old), but i had to use semicolon ” ; ” instead of colon ” , ” in the formula.
Hi Piotrek,
Yes, you’re right! This is a regional change that’s standard for syntax for continental Europe.
Cheers,
Ben
Hi there,
I’m trying to use this method for Street Easy listings. Mine will work and then I’ll come back to the sheet later and get the “Error
Imported content is empty.” and ideas why this might be happening?
Thanks
As someone who uses programming for web scraping, this article was very helpful. I often start with complex frameworks like Scrapy for Python, not realizing there are simpler solutions out there. Cheers, Simon
True! Although they are limited compared to Python, these IMPORT functions can do a surprising amount. I did a follow up article about web scraping social media statistics.
Hello Ben;
First of all, I would like to admit that those infos are awesome and amazing, thank you so much! and I would like to ask you 2 more questions;
1-Is there a way to grab the data from website which includes multiple pages?
2-(Actually, this question depends on your response to the 1st question) So, if there is a way for pagination then is there an automated way to grab the data from the pages which require age verification (by entering the birth date) among those multiple pages?
Sorry for my bad English I hope that it is good enough to make you understand my questions 🙂
Thank you in advance
Regards
Hi Ozan,
So there’s no way for standard formulas to deal with pagination and scrape data from multiple pages. Potentially you could modify the URL each time, depending on how it was set up, so that you could change the pagination number each time, e.g.
In one cell put https://techcrunch.com/page/2/
then in next cell: https://techcrunch.com/page/3/
In next cell: https://techcrunch.com/page/4/
etc..
and then run the IMPORT formula for each of those.
There’s no way you can grab data that requires age verification first, without using Apps Script to programmatically do that. The IMPORT formulas are pretty basic (but powerful!).
Hope that helps!
Ben
Thank you so much for your response Ben
Hi Ben,
I’m trying to scrape a value for a crypto coin from this page
https://bittrex.com/Market/Index?MarketName=BTC-ANS
The value I want is in the html as this
0.00203969
I’ve tried a few different syntax, for example this
=importxml(A1,”//span[@span data-bind=’text: summary.displayLast()’]”)
But cannot find the correct syntax.
Could you help out please.
Thanks
Hey Sean,
Unfortunately I don’t think it’s going to be possible with these IMPORT formulas, as the Bittrex site is dynamically generated client-side javascript. I’ve tried all the tricks I’m aware of, but can only get the static parts like headings, not any of the data. Read more about this problem here: https://www.benlcollins.com/spreadsheets/import-social-media-statistics/#notWorking
Your next step would be to look at writing some Apps Script to extract this data via the API they have (docs here: https://bittrex.com/Home/Api).
Cheers,
Ben
Sean – there is an alternative site with Bitcoin prices, coinmarketcap.com, that does work for scraping data from. Have a look at this comment thread: https://www.benlcollins.com/spreadsheets/saving-data-in-google-sheets/#comment-34170
Might be useful to you?
Thanks Ben that is great, next question might be daft but once I’ve pulled that data how do I use it in anther formula on the sheet?
I’m trying to calculate a sum using that price value * how many coins I hold and it isn’t working.
Thanks!
Hey Sean,
I found this formula
=IMPORTXML(A1,"//span[@id='quote_price']"), with the URL in cell A1, worked ok to use in other formulas (e.g. sum). I had the cell formatted as a number (or accounting). You can also try wrapping your existing formula with the VAlUE formula, like this:=VALUE(existing formula in here)Hope that helps! Feel free to share your formula if it’s still causing issues.
Ben
Sorry Ben you lost me 🙂
At Q1 I have the URL http://coinmarketcap.com/currencies/antshares
At O1 I have this =IMPORTXML(Q1,”//span[@id=’quote_price’]”)
O1 is formatted as Financial but still for some reason has the $ symbol
At L13 I have a sum of my coins
At L15 I’d like to have a calculation and have tried this but its not working =sum(L13*O1)
Not sure what you mean by wrapping the existing formala with the value parameter.
Can you explain with an example as per my fields above?
Many thanks!
Sean
Hey Sean,
The $ is just formatting that’s been added, it’s still a number.
If you have your total number of coins in cell L13, using the SUM formula, e.g. SUM(L1:L10) say, then you just need to multiply that by the $ rate from the IMPORT formula in cell O1 to get the value, you don’t need to use the sum here as well.
Cheers,
Ben
I’m obviously doing something wrong….
L13 value is 120
L10 value is 10
at L15 I can do =sum(L13*L10) and I get the expected result of 1200
At O1 I have the imported value $8
If I try to get a total using that value as follows =sum(01*L13)
Instead of a number I get #VALUE!
I don’t see what the problem is 🙁
Sorry, just seen this
Error
Function MULTIPLY parameter 1 expects number values. But ‘$8.04’ is a text and cannot be coerced to a number.
I’ve formatted O1 as Number – Financial
Any idea why it is still being treated as text?
Not sure why yours is showing up as text, so you could try the following two tricks wherever you want to use O1, replace with:
VALUE(O1)or
O1 * 1
Feel free to share your sheet if still no joy!
Hi Ben,
Neither of those things worked.
Please have a look here, I think its self explanatory which fields are broken.
https://docs.google.com/spreadsheets/d/1JYFWwBgiyByOOlxU_BuwZZmVLHOKTx0Nk9_65q4Ax7c/edit?usp=sharing
Many thanks!
Hey Sean,
Honestly not sure why it’s being imported as text with a “$” at the front and not being recognized as a number. Anyway, here’s a new formula which will just deal with this issue (I’ve updated your sheet with the formula in the yellow box):
=iferror(value(IMPORTXML(Q3,”//span[@id=’quote_price’]”)),value(substitute(IMPORTXML(Q3,”//span[@id=’quote_price’]”),”$”,””)))
Hope that helps! Once it’s sorted I’ll remove the link to your sheet from the comments here.
Cheers,
Ben
Hi. I understand that this post is from 2016, but if you help me I’d appreciate. I’m getting the same error, but with the command “IMPORTFROMWEB”:
=IMPORTFROMWEB(“https://ca.pcpartpicker.com/products/video-card/#m=8,14,18,27,252,43&xcx=0&N=2,3&sort=price&c=501″,”/html/body/section/div/div[2]/section/div/div[2]/div[1]/div[4]/table/tbody/tr[1]/td[10]/text()”,”jsRendering”)
To scrape the price from the first product, which in this case is $499.99 (for the prodcut MSI MECH 2X OC as for 13/12/2022). The formula correctly gets the price, but I get the same error while trying to multiply it:
Function MULTIPLY parameter 1 expects number values. But ‘$499.99’ is a text and cannot be coerced to a number.
Using the command belows works fine:
=IMPORTFROMWEB(“https://uk.pcpartpicker.com/products/video-card/#m=8,14,18,27,252,43&xcx=0&N=2,3&sort=price&c=501″,”/html/body/section/div/div[2]/section/div/div[2]/div[1]/div[4]/table/tbody/tr[1]/td[10]/text()”,”jsRendering”)
Which scrapes the price from the UK domain of the site, and wields a price with a £ symbol, and not $.
Thank you for your time.
Hey Ben,
Thanks for the example. I’m trying to get the only number available in this URL: https://blockexplorer.com/api/status?q=getDifficulty
When I hit “inspect item”, it doesn’t seem to have any tags, headers and it’s not even defined explicitly as an HTML or XML document -it’s just plain text! And I can’t find the right syntax using the IMPORTXML function so that Google Sheets likes it. I just keep getting a #N/A or #VALUE!
I’ve been trying to put in wildcards and some other things, but I can’t get it to work…
Hey Daniel,
Assuming you have that URL in cell A1, then you can use this formula to get the data into your Sheet:
=importdata(A1)To extract just the number, try the following formula:
=regexextract(importdata(A1),"\d+.\d+")Hope that helps!
Ben
You’re the man, Ben! Works like a charm.
Hi Ben,
That was very helpful.
I have a question. How can I get multiple data from a web page.
For example: I want to extract all the image URLs and the corresponding alt tags from a list of web pages.
Could you please explain?
Thanks,
Abarna
Hi Ben,
I’m having a similar problem to those above regarding Crypto Currency sheets. I have successfully managed to pull current values from coinmarketcap.com and it’s working well. However, I’m now trying to pull data from another site https://www.cryptocompare.com/coins/ndc/overview to be specific, using this formula – =IMPORTXML(J23,”//div[@class=’price-value’]”).
I’m pretty sure I’ve made a fundamental error, but I only found out this was possible yesterday….lol I’ve been trawling youtube and forums for a solution and stumbled upon this one… The above is the best I’ve managed to come up with. Any help with this would be appreciated.
Cheers
Carlton
Hi Ben,
Thanks for answering all questions, I am having an issue could you please address it.
Issue: I am trying grab data from google maps url (https://www.google.com/maps/place/Inox+Movies+-+LEPL+Icon/@16.5027383,80.657804,17z/data=!3m1!4b1!4m5!3m4!1s0x3a35fac8af6a8e6f:0x31b258f18dfbe910!8m2!3d16.5027383!4d80.6599927)
from this url I would like business name it is in below format
(Inox Movies – LEPL Icon)
Formula is
=query(importxml(A1,"//h1[@class='section-hero-header-title']"))I am not getting any data(showing : ErrorImported content is empty.) so could please verify once and correct us what we are doing wrong.
Thanks in advance…
Hey Sivaji,
I’ve tried to extract this data too but unfortunately haven’t been able to either. Not sure it’ll be possible with these IMPORT formulas
Hi Ben,
Thanks for the article, it looks great and it looks you’re answering all beginners’ questions!
I am trying to do this:
1. the following web page (http://www.gcatholic.org/events/year/2017.htm#end) lists all nominations and resignations from bishops in the Catholic Church.
2. I would like to regularly import into a google spreadsheet first name, last name, title, and country of the lastly nominated bishops (and only the nominated, not the info concerning those who resigned or so).
I was trying to do it by myself after reading your article, but it’s more complicated than I thought, and I’m pretty much a beginner.
Thanks for any help,
Cédric
Hi Cédric,
You can use this formula to quickly get all the data from that page into your Google Sheet:
=importhtml("http://www.gcatholic.org/events/year/2017.htm","table",4)This should save you some time. The quickest way to then extract details from this data is probably manually, because the data in unstructured, i.e. textual, so it changes from row to row.
Hope that helps!
Ben
Thank you Ben.
Your formula kind of works, but I guess I was too ambitious in wanting to import from an unstructured page.
Cédric
Hello Ben,
Your Article is really helpful. Thankyou for using query function here. Unfortunately your suggestion can’t solve my problem. I want to explain you with this image below:
https://cdn.pbrd.co/images/GNYpBTL.jpg
I am scraping data from collins thesaurus for different word collection of my own. When i scrape data from collins i get more than 15 synonyms and their respective examples in new column with each synonym in new row. The above image has synonyms and respective example of synonym in 3rd, 4th column with covering all the rows of 3rd and 4th column of sheet for single word Constitution. As it enters many rows i can’t use the Importxml function on other rows for different words in image. With your example it becomes cumbersome to add offset to 15 different synonyms. So what i want is to scrape data in the way that all synonyms and their respective examples in a single row itself. Is there anyway to do it?
Hey Bharath,
Try wrapping your function with the
transposefunction, so it’ll look something like this:=TRANSPOSE(IMPORTXML(...))That should transform the data into two rows for you. It a lot more complex to get that data into a single row in the correct order, but it’s possible. Have a look at this example sheet: https://docs.google.com/a/benlcollins.com/spreadsheets/d/1e-mjf_HNWyYvkhFYWqRb2lTanAx77l-YXZO1YYPs71w/edit?usp=sharing
Hope that helps!
Ben
Hi, great post and resources B.
Would you happen to know the importxml Google sheets function to identify if site is using VideoObject schema like this?
{
“@context”: “http://schema.org”,
“@type”: “VideoObject”,
“name”: “Title”,
“description”: “Video description”,
“thumbnailUrl”: [
“https://example.com/photos/1×1/photo.jpg”,
“https://example.com/photos/4×3/photo.jpg”,
“https://example.com/photos/16×9/photo.jpg”
],
“uploadDate”: “2015-02-05T08:00:00+08:00”,
“duration”: “PT1M33S”,
“contentUrl”: “http://www.example.com/video123.flv”,
“embedUrl”: “http://www.example.com/videoplayer.swf?video=123”,
“interactionCount”: “2347”
}
James – can you share the url? Hard to know without the context…
Ben, it seems like you are the guy to turn to for extracting data from web pages. So here goes:
1. I have a list of business entities in a Google Sheet and the name of the business entity is a hyperlink and I want to extract the hyperlink to a cell in the same row.
2. The link that was just discussed above then takes me to a page with information for that business entity – see this example – http://www.americanwineryguide.com/wineries/bridge-press-cellars/
3. I am looking to the pull details like – address, email, phone, founded, cases, etc. into cells in the same row.
What do you think?
Hey Doug,
Yes, this should be possible, based on the url you shared. The IMPORT formula to extract the data for that example is as follows:
=importxml(A1,"//div[@id='winery_detail_box1a']")The
//div[@id='winery_detail_box1a']might vary for different websites, so you have to use the Inspect Element function to find the identity of the element (see post above).Cheers,
Ben
Hello Ben!
Thank you for a very helpful guide! I have been testing this out on several pages and it works perfectly.
However, I fail continously on this site (in swedish)
http://www.morningstar.se/Funds/Quicktake/Overview.aspx?perfid=0P00009NT9&programid=0000000000
I’m trying to extract e.g. the table with “Årlig avkastning %” as headline . Actually I can’t extract anything from this page without using IMPORTDATA.
Additionally, chrome addons e.g. Scraper can extract with the XPath
“//*@id=”ctl00_ctl01_cphContent_cphMain_quicktake1_col1_ctl00_ctl04″]/table”
But I fail in my Google Sheet so I suspect it has something to do with Java?
Do you have any proposals?
Hey Emil,
If you use the IMPORTDATA function and scroll way down the data (line 1075 for me), you’ll see the data table for Årlig avkastning %. However, it’s obviously not very useful in this format. You may be able to extract with REGEX formulas but it would be pretty difficult to do…
You’re right that the IMPORTXML function does not seem to be able to return anything. Most likely because the page is being (partly) generated by javascript.
Cheers,
Ben
I m trying to fetch stock data from this link
http://www.bitcoinrates.in/
but I m not getting prices of stock just the name is return I m using this
=importxml("http://www.bitcoinrates.in/", "//tr[@class='exchange_row']")Hey Ritu – Unfortunately I don’t think you can with these formulas. The values are being generated by javascript, so the actual
tdandspan‘s are just empty placeholders for the javascript to insert values into. If you try doing=importdata("http://www.bitcoinrates.in/")you’ll see that the tables are blank.Hi Ben – This is AMAZINGLY helpful. Thanks for the post.
I scraped from https://comicbookroundup.com/comic-books/reviews/dc-comics/action-comics-(2011) where the url is in D2 on Google Sheets using
=importxml(D2,”//td[@class=’rating’]”)
Any suggestion on how to scrape an individual number (ex: #1) so that I can display them all individually?
Thanks x 1000
– Robi
Hey Robi,
Finally catching up on comments.
You might be better off grabbing the whole table by using the IMPORTHTML formula like this:
=importhtml(A1,"table",2)That way you get all the columns.
If you wanted to then extract a specific entry, you can use the QUERY function to pull that out:
=query(importhtml(A1,"table",2),"select * where Col2='#52'")where in this case I have specified that I want #52.
Hope that helps!
Ben
Hi Ben-
How can I import into googlesheets from this website: https://www.covers.com/Sports/NBA/Matchups?selectedDate=2017-12-04
I am trying to import table but keep getting errors. I opened the source code but I couldn’t determine what # table to pull.
Hi,
Thanks for sharing useful information !!
HI BEN,
JUST NEED TO KNOW IF THERE IS ANY WAY TO PULL ALL WEB PAGES DATA WITH ONE IMPORTXML FUNCTION , ??
REGARDS
Hi Ben,
Is it possible to do the same from google trends and whether a line chart in the website can be pulled as a table using importxml()
thanks,
Sid
Hello
i have a trouble, may be you can help me…
ask write here – https://docs.google.com/spreadsheets/d/1N83IqaBJNiQtyEhDtszTkG8JZUeJkAHjbTjnfM9-1_o/edit#gid=235706254
its about =IMPORTXML or =IMPORTHTML or =IMPORTDATA
Hi Andrii,
It usually takes lots of trial and error to find the right function!
http://www.bursamalaysia.com/market/listed-companies/list-of-companies/plc-profile.html?stock_code=5218
I cannot grab the last done price. I get #N/A. Please help
Hi Ben,
Many thanks for your article.
I’m trying to scrape data from a website with an attributes list like this:
Design:
Winter boots
Recommended use:
Everyday; Leisure; Winter hiking
All the elements have the same class. How can I solve this?
Hi Ben,
Wow, this is a super interesting post…. I’m no Google Sheets wizard either, but even a beginner like me can see how powerful something like this could become.
If I want to check URL/link status (similar to this post…https://medium.com/@the.benhawy/how-to-use-google-spreadsheets-to-check-for-broken-links-1bb0b35c8525) for hundreds of URLs at a time, wouldn’t the website ban my IP?
I’m just wondering if I use these “fetchURL” or “IMPORTXML” codes/formulas on my Google Sheet, won’t I run into trouble with the site I am scraping? Does Google Sheets use my laptop’s IP address to conduct these URL fetch commands or am I safe to run hundreds of these checks at a time?
I have hundreds of links pointing to the same site on my sheet at the moment so if I create the formula and drag it down my sheet I’m scared I may get my IP banned!
Thanks for your time and attention with my NOOB question and again, great work on this post.
Ben,
This is a great resource! Thank you. I’m wondering if you can tell me whether data from this website – http://www.bet365.com (specifically, say NBA data: https://www.bet365.com/?lng=1&cb=10326513237#/AC/B18/C20448857/D48/E1/F36/P^48/Q^1/I) – can be imported into Google Sheets? I’ve had success with other sites but cannot get this one to import. I’m guessing it’s un-scrape-able but can you confirm?
Thanks!
Chris
Hey Chris,
Yeah, I wasn’t able to get that one working either. ¯\_(ツ)_/¯
Ben
hi, thanks for sharing such a useful article. but can import formulas can be used in a use case in which user is filling the google form, regarding his/her personal details and after filling the details will be paying for his stuff through paytm, and parallely all the details have been stored in google sheet, but once the payment is done on paytm, then in google sheet that column is updated automatically with a status of “payment received”, who have done the payment.
is this possible with web scrapping. please let me know
i hope i am able to explain the use case.
Hi Ben – AWESOME guide!
Can you help with this, I’ve tried multiple ways to pull Amazon Sales Rank, but something’s not right! Thanks
https://productforums.google.com/forum/#!topic/docs/8k-FcuXgbNw
Hi Naeem,
Try this formula to grab all the Amazon ranking data:
=index(importhtml($A$2,"list",10),9,1)This uses ImportHtml to extract the list from the Amazon page that contains the ranking data, and then uses an Index wrapper to extract the 9th row of the array, which has the ranking data in.
To get an individual ranking number, extend it to this:
=value(regexextract(index(split(index(importhtml($A$2,"list",10),9,1),"#"),1,2),"[0-9,]+"))This splits the result by the “#” to get the different rankings, Index to get the relevant part of the array and then Regexextract to grab the numbers and Value to convert them from strings to values.
Hope that helps!
Ben
Hi Ben,
Can you help to grab the Amazon Bestseller-Rang in this example?
https://www.amazon.de/dp/1729361862
Should be “1.151” but using your formula I get #N/A
Thanks, Dominik
Thanks Ben, really good article and I made use of it but I’m also frustrated with the “Loading” error. It’s not even consistent. Do you have any idea how to circumvent it, maybe?
Thanks Onder. Yes, these formulas can be temperamental, not sure there’s anything you can do about it though. Once you’ve used them to gather your data, I’d suggest converting them to static values, so you don’t lose the data if the formula stops working.
How do i import specific price from a website to google sheets
Ex:
website is “https://www.amazon.in/gp/product/B06W55K9N6/ref=ox_sc_act_title_4?ie=UTF8&psc=1&smid=A14CZOWI0VEHLG”
price tag is 5899 and its
xpath is //*[@id=”priceblock_ourprice”]
but when i use formula
=IMPORTXML(https://www.amazon.in/gp/product/B06W55K9N6/ref=ox_sc_act_title_3?ie=UTF8&psc=1&smid=A14CZOWI0VEHLG, //*[@id=”priceblock_ourprice”])
giving me #ERROR!
Hi Ben! Thank you for this insightful article. I was wondering if this web scraper formula will work with websites like SimilarWeb, where I want to extract the integer value for the amount of traffic that a specific website is receiving as shown on the SimilarWeb results? Thank you!
Hello Ben
Wondering if this method or similar works to extract specific data off pdf documents. I need a similar system to enter data from my google sheet into a website’s data, click through to a specific link on two consecutive pages, and then scrub data from a pdf.
The website is http://nycprop.nyc.gov/nycproperty/nynav/jsp/selectbbl.jsp
For example
Borough: 1
Block: 40
Lot: 3
Page 1 – View Quarterly Prop Tax Bill (QTPB)
Next Page – Click to view QPTB
Scrub Mailing address from pdf
Hi Ben
This is amazing! has solved so many problems for me!
Does the data automatically refresh as it updates on the page it is pulling from or is there additional work to do to make it update regularly?
Cheers
Hi Geordie,
By default, these functions recalculate as follows:
ImportRange: Every 30 minutes
ImportHtml, ImportFeed, ImportData, ImportXml: Every hour
Read more in the docs section here: https://support.google.com/docs/answer/58515
Cheers,
Ben
Can the importHtml formula triggered in 1min interval using any script?
Hi Ben,
It is been very good experience reading and watching your training and support material.
1. I have a query using IMPORTXML, how we can replace empty or missing data point in a whole datalist by some value or “NA”?
2. How we can extract SRC image or link of image in the spreadsheet using IMPORTXML
Thanks in advance!
Navdeep
HI Ben,
I want to import a table from web. I can do that using importhtml formula. But it is not updating automatically even setting a trigger with GAS. Can you help me to update the table automatically once it is updated in web?
Thanks
Hi,
I want to grab all member list name from a my Facebook Group ?
is possible?
Hi Ben, I hope you can help me getting the data on the right into my google spreadsheet: https://www.dukascopy.jp/plugins/fxMarketWatch/?swfx_index
I tried the following which did not work: =ImportXML(“https://www.dukascopy.jp/plugins/fxMarketWatch/?swfx_index”,”//div[@class=’F-qb-Gb’]”)
What did I do wrong or is this impossible to be imported?
Thx, Oliver
Hi Ben,
I’m struggling to get some data from the ManoMano website into a google sheet.
I have a list of ME references which I can easily combine with the search request to give me a working url like : https://www.manomano.fr/recherche/ME4326301
Using Regexreplace and importxml I can get the title but I’m looking to identify both the category (listed as a breadcrumb in the XML path) and the sellers name (which has //*[@id=”js-product-content”]/div[1]/div[2]/div[3]/div/div/p/a as the xml path).
I can’t get either to extract to a google sheet.
Hi Ben, what a great solution, thanks! I have a question: how can I scrape the price from this html source?
€132,95
Oops, html sourecode is filtered, of course. It’s the price ( 132,95) mentioned on this page: https://www.bever.nl/p/fjaellraeven-greenland-top-rugzak-NAAEC80001.html?colour=4324
Hey, I had a good play and managed to extract the title on this page
https://www.banggood.com/UMIDIGI-One-Max-6_3-Inch-Global-Bands-4150mAh-NFC-4GB-RAM-128GB-ROM-Helio-P23-4G-Smartphone-p-1393215.html?utmid=6224&ID=533906&cur_warehouse=HK
I’m trying to extract the image URL, however, none of the attempts I’ve tried have yielded success. Any thoughts? Also, thanks a lot for this guide, it’s been extremely useful!
Very valuable information! Thank you for putting together. What is your advice for scraping a site when the page is partly or wholly generated by javascript? Is there any recourse?
Hi ben, this post is one of the wonderful in my experience.
I am trying to scrape a table to google sheet from
https://www.indiainfoline.com/markets/derivatives/long-buildup
xpath query is //table[@class=’table table_mkt fs12e mb0′]
I wanted to scrape tabe of stock futures current month expiry
This is only giving me titles not actual data
Can you please look into this?
Thanks in advance
Hi, Ben
Do you know how to use google sheet to scrape Youtube comment counts & share counts? Thanks
Hello Ben,
I’ve been trying to get the title of one google sheet imported into another. The HTML source code shows File 101218, so I used this:
=IMPORTXML(I$1,”//span[@class=’docs-title-input-label-inner’]”)
but it produced ‘Error – imported content is empty’
I right-clicked in the devtools html view and saw there was a Copy > Xpath menu item. I gave that a go and it resulted in “//*[@id=’docs-title-widget’]/div/span”, which I made into the formula
=IMPORTXML(I$1,”//*[@id=’docs-title-widget’]/div/span”), correcting the double quotes to single.
I have no idea why this is different from the first version, but it also produced the ‘Error – imported content is empty’ message. Bearing in mind the initial HTML I pasted above, do you know what’s going wrong here, Ben?
Sorry, the html pasted was this
span class=”docs-title-input-label-inner”>File 101218</span
I have removed a couple of brackets so it isn't mucked up by the form validation
If I am using IMPORTXML for web scraping how would I account for empty or missing values under a certain SPAN class? Basically I want that value to display as a blank cell in my spreadsheet vs just skipping to the next value on the website.
Is there a way to add information like the high and low on chart from https://money.cnn.com/quote/forecast/forecast.html?symb=NFLX to google sheets?
I have a list of hyperlinked text and need to pull an address, number, and a name from the site. Unfortunately, this info is not in a table or XML… how can I pull text from each individual site that is separated by HTML breaks?
https://www.nj.gov/dcf/families/childcare/centers/Hudson.shtml
Hey Ben,
Would the data update if the data on the website updated?
Thanks. This works on paper, but won’t work for many sites in practice. Example: =importxml(“https://www.amazon.com/dp/B000ND74XA”, “//title”) results in “Robot Check”.
Hey Ben,
I am unable to import the data from Mode analytics in spreadsheet by using your formula importHTML(url, query, index) so you could you please tell me that how to solve this issue.
can you explain how to extract some images URL from a google search based on a keyword? I have a spreadsheet with some products titles and want to put 1 o 2 images URL for each product in the cells beside the title cells. The products titles would be the keywords.
Hi Ben, is it possible to scrape the “Total Visits” number from this page? https://www.similarweb.com/website/billboard.com#overview
I’ve been fiddling around with it but can’t get it to work.
Hi Ben
Thanks for a great resourse to Google Sheets!
Is it possible to scrape data once a day on a page behind a login?
regards,
Chrilles
Hi Chrilles,
You can’t use these IMPORT formulas to scrape data behind a login. You’ll need to use Apps Script to connect to that service’s API (assuming they have one). Here’s an intro to APIs here: https://www.benlcollins.com/apps-script/beginner-apis/
Cheers,
Ben
Hi Ben,
Your article on webscraping and the examples are very helpful. No doubt you are the guy I can look to in extracting data from the below web pages.
url: https://www.bseindia.com/corporates/ann.html
At the category drop down menu I choose “Company Update”. When I inspect the element, I do not find “Company Update”. I would like to do the following
1. Scrape all the urls for all companies under “Company Update” for the day.
2. Scrape all the urls for a list of companies in my google sheet under “Company Update” for the day. In respect of this second query, let us say I have the company codes as below 540691, 535755, 500410, 512599, 542066, 532921, 533096, 539254, 540025. (The company codes are similar to symbols used by NASDAQ like AAPL for Apple Inc). I could expand the list.
Please let me know how to crack this.
Thanks
Tundul
Hi Ben!
Was wondering, if you know what user agent GoogleDocs is using when performing the scrape? Im getting a fetch error but the content is available as rendered serverside so I guess there might be some kind of IP or useragent restriction. Id like to check that, but am not sure if this user agent:
Mozilla/5.0 (compatible; GoogleDocs; apps-spreadsheets; http://docs.google.com)
is indeed the only one that Google Sheets is using? Any idea? thanks
Hi there
Does anyone know how I return a list of the URLs on a given page. I have worked out how to get a list of the URLs but they only give the text on the URL e.g. the wording on a CTA button not the URL itself.
This is the code I am using for this website:
https://www.pizzaexpress.com/wardour-street/book
The above URL is in cell A2 (returning Book now for 36th link on page)
=INDEX(importxml(A2, “//a”),36)
Returns Book now correctly but I need the link being used for Book now too.
Thanks!
Hey,
Quick question, the table I am looking to import has multiple pages. How do I get all of the data into a google sheet without it cutting off at the first 50 lines?
Thanks
Hi Ben,
I downloaded your solution file, but I get an error: the imported content is empty.
Regards,
Hi Ben,
My file is a publicly available NARA (National Archives) file download formatted and expanded with formulas, etc.
A couple “index/match” formulas in column C & column AB lookup the state that assigned each SSN and the city state corresponding to the person’s zip code at the time of death. Column C, the assigning state is easy – populates 100% of the time. Column AB however, accesses the table in sheet 2 “Master 5-Digit…” which includes 33000+ zip codes but actually excludes quite a few. As many as 10% of the lookups return no match. So, how to automate?
I thought importxml should work but as you can see, I get nonsense. I can’t find an example that shows this use case: where the specific web page is dynamic based on the 5-digit value in column AB. It seems super simple conceptually. Is there a way you think of doing this to simplify the syntax versus the squirrelly way Googlers think about it and thus explain it in the examples that are available online?
I’ve spent hours on Youtube and trying to work through the syntax to save the time required to manually look up each record that doesn’t come through.
I appreciate any help you can provide or resource you can point me to.
Thank you,
Stacey
Here is the file: https://docs.google.com/spreadsheets/d/1W12KBmwqVMSkWiAH-0BOnK9tU-M7uE6mO0pcZDjIMMw/edit?usp=sharing
Is there a way to get data from a website I have access to that is passworded? e.g. my data on Spreaker.com
Not with these formulas, unfortunately. You’ll need to connect to the website’s API (assuming they have one) and authenticate your app. There are third-party tools that connect to certain websites (e.g. supermetrics) or you can code it yourself with apps script (see this article for help getting started with apis: https://www.benlcollins.com/apps-script/api-tutorial-for-beginners/)
Hi Ben,
Great post and sharing. I am very new to this topic and would like to scrap the stock price and other information from the following sites:
https://www.gurufocus.com/stock/V/summary
https://www.morningstar.com/stocks/xnys/v/quote
https://sg.finance.yahoo.com/quote/V
https://www2.sgx.com/securities/equities/CRPU
https://www.propertyinvestsg.com/singapore-reit-data/
https://sreit.fifthperson.com/
Tried to follow your example but gave errors. Can the formulas be used for these sites? Would it be possible if you provide some examples from these sites for me to start with?
Thank you.
Hi Ben,
Thanks for sharing. It is very helpful.
A)
For the following sites, I am able to retrieve the whole table using ImportHTML():
https://www.propertyinvestsg.com/singapore-reit-data/
https://sreit.fifthperson.com/
Is there a way to get only the price based on specific stock?
B)
For below site:
https://sg.finance.yahoo.com/quote/V
I am able to get the whole string i.e.
V – Visa Inc.NYSE – NYSE Delayed Price. Currency in USD 189.39+0.23 (+0.12%)At close: 4:00PM EST
How to get only get the stock price?
C)
Unfortunately, I am unable to get any result (i.e. #N/A) for the following sites using ImportXML():
https://www.gurufocus.com/stock/V/summary
https://www.morningstar.com/stocks/xnys/v/quote
https://www2.sgx.com/securities/equities/CRPU
Most of the stock prices and information are from these sites. I appreciate your advice on how I can retrieve the stock price as well as other information e.g. P/E, Quick Ratio, etc. from these sites.
Looking forward to your reply.
Thank you.
Hi Ben,
For the following site:
https://sg.finance.yahoo.com/quote/V
I am finally able to get the stock price using the formula:
IMPORTXML(Concat(“https://sg.finance.yahoo.com/quote/”,”V”),”//span[@data-reactid=’14’]”)
However, when I tried to change the second parameter in the Concat function as a variable, and apply it to a list of 340 stocks, it is taking a long time to load all the values and many are showing as “loading”.
Is there a more efficient way to retrieve the prices?
Thank you.
Hi Ben!
Is it possible to scrape traffic data and other data from similarweb.com? I tried this but it did not work (I did check that it is pointing to the right cell).
https://www.similarweb.com/website/radarcupon.es
=IMPORTXML(B4,”//span[@class=’engagementInfo-valueNumberjs-countValue’]”)
Thanks for your help!
It seems that they use the same class for different values so that might be the problem? I would be greatfull if you can give me an example of the formula to be used for this.
were u able to get this working with similar web?
Hey Alba,
I am not Ben but I assume I can help you, too.
=importxml(B4;”//span[@class=’engagementInfo-valueNumber js-countValue’]”)
Please note the space character between “…valueNumber” and “js-…”.
Best regards
Jörn
Thanks for helping, Jörn!
Hi Ben,
I have been trying to import a table from ESPN for PGA player stats. The URL is – https://www.espn.com/golf/leaderboard/_/tournamentId/401155427
and when using importhtml it gives me the leaderboard data. The table I want is from the 2nd tab on the page – Player Stats, but the URL does not change when clicking on it, so I continue to get the leaderboard data. Is there a workaround? Thanks
Hi Ben,
Not sure this will be the same formula but I’m trying to extract the company name from a company domain… any ideas?
for example if I have the domain thinkstream.com.au in one column I would like to have the company name ThinkStream appear in a second column.
Thanks in Advance!
Hi,
Is it possible to create a spreadsheet that includes data from a single page, plus data from links from that page?
For example, this dataset shows everyone incarcerated in Alachua County jail. Each person’s name links to more information about them. Is it possible to create a table with each person’s name, plus data from within each person’s page?
http://oldweb.circuit8.org/cgi-bin/jaildetail.cgi?bookno=ASO20JBN001149
For example Name, Total Bond, Booking Date, etc..
Thanks!!
Hi Ben,
I was wondering if it is possible to scrape the values from a drop-down list?
Thanks!
Is there a way to scrape the Fuel charge from UPS into Google Sheet with the most recent value.
https://www.ups.com/us/en/shipping/surcharges/fuel-surcharges.page
Sincerely,
Benjamin
Hi Ben, many thanks.
Is it possible to import YouTube playlists?
Thanks
Hi Ben, Following you for years now!
With Facebook is there a way to discover the last updated post was in a group?
“Great post. I was checking constantly this weblog and I am inspired!
Extremely useful information specially the ultimate section 🙂 I deal with such information a lot.
I was looking for this particular info for a long time.
Thanks and best of luck.”
Hi Ben!
GREAT ARTICLE!
I’m trying to scrape the traffic information from Similarweb from a list of websites.
I’m having trouble finding what is the identifier for the data, even tough I can clearly see it on the website.
Can you help me with the formula, please?
Thanks in advance,
Bernardo
This worked like a charm for me! Just had to experiment, like you mentioned, with the table number in the importhtml function, and it brought in the data perfectly. Outstanding! Oh the things that make us happy 😉
Hey guys! Great guide!
I am looking to get the values from osu! Profile pages like this one: “https://osu.ppy.sh/users/5529199/fruits” . I am mainly trying to get the Global Ranking, Country Ranking, and the number under “PP” on the pages near the line graph.
I have been trying to get the importxml formula to work for these 3 values, but most things I try all return N/A saying that it can’t find the values etc. Looking at the elements, it seems like the numbers are burried under alot of div layers, but still no luck even copying the Xpath from the site.
Anyone have some ideas on how I can get these numbers? As I am trying to put together a spreadsheet for a tournament we are running, and these numbers update regularly, so manual entering isn’t really an option.
Thank you for your tine 🙂
Hi Ben, I’m trying to extract the dispatch date element on the Amazon page: https://www.amazon.co.uk/dp/B00J8I72PQ , but when I try to inspect the element I can’t see the text to trigger it to show delivery date, below is the code I get.
Thanks in advance,
Tom
FREE Delivery
Sep 22 – Oct 21
for Prime members
Details
This worked like a charm for grabbing securities prices off Bloomberg for TSE stocks not supported by GOOGLEFINANCE. Thanks!
You’re welcome! Cheers.
Hello, I am trying to extract the prices from Aliexpress website, is it possible? I couldn’t do it! can anyone help me?
There is no solution for SimilarWeb monthly visits scrapping problem?
:/
Kinda the hardest thing to scrap..
Hey Ben!
Can we get all the reviews from Google Playstore in Google sheets?
Hi Ben,
I’m trying to get the table from https://economictimes.indiatimes.com/marketstats/exchange-nse,marketcap-,pid-40,sortby-indexName,sortorder-desc.cms
I have tried ImportHTML, ImportXML but have no avail. Would be great if you can tell me if it can be imported or not.
Hi,
I was wondering if there is a formula to use query to get data from another sheet and filter date using date in data validation
Hi Ben! Thanks for your guide. I am trying to use this formula but getting N/A. How should I phrase the forumla to output the h1 from this page:
https://wiu.campuslabs.com/engage/organization/159bcm
Output should be “159 Baptist Collegiate Ministry at WIU”
Thanks in advance!!
Ben,
I am trying to pull the “miscellaneous stats” table from https://www.basketball-reference.com/leagues/NBA_2021.html . I was able to pull tables up to #4, any table value I use after that does not supply me with any information. I went ahead and attempted up to #50 hoping it was a weird mishap but did that without any success. I tried looking through the code in hopes I could find the table # and failed there too….
if you find any success in this that would be great!
Thanks
Hi! thanks for the very useful information, i try to capture the other web page, and i found it difficult for “dynamic data”, which is change by time, such as the result of this formula,
=importxml(“https://www.myethshop.com/”, “//*[@id=’now_timestamp’]”)
only shown “–“, why?
hope you could help me to solve, thanks
Hey Ben. Great Post!
I have one question. Is it technically possible to extract the value of an attribute using this method?
Thanks.
Hey Ben!
Great post learnt a lot.
I am a project in India where we curate online videos for children who are currently out of school due to the pandemic. We have a list of youtube videos already curated – what we want is to get the names of all the youtube video owners / channel names. Will that be possible with this?
https://www.youtube.com/watch?v=dzOP7jliAKM – one such video for example
Hey! Great article. I’m trying to use your tutorial to grab a checklist of baseball cards in a table and put them in a sheet. Would you mind taking a look and let me know if your method is possible here: https://www.psacard.com/psasetregistry/baseball/modern-player-sets-1970-present/nolan-ryan-master-set/composition/1944
Hi Ben, Thank you for your tutorial. I tried the following code to fetch the result of the number of jobs from Linkedin but it doesn’t seem to be working. Can you help? Thanks
Cell A1:
https://www.linkedin.com/jobs/search/?f_TPR=r604800&geoId=105663381&keywords=ux%20designer&location=Surrey%2C%20England%2C%20United%20Kingdom&position=1&pageNum=0
=IMPORTXML(A1,”//span[@class=’results-context-header__job-count’]”)
Hey Ben
Would this approach work for scraping Google Workspace reviews?
If not, what would you suggest?
Could this be used to scrape pricing on Google shopping?
Awesome content, thank you! Do you scrape FaceBook Marketplace?
Nice to find this content. Google Sheets is now a must in SEO.
The issue I’m facing is if the line has td class=”bocss-table__td bocss-table__td–data” where the number is followed by a .
Hi Ben,
I tried using the first formula but it gave me N/A error in B1. Any idea what the problem could be? I’d appreciate your response. Thank you.
Hi Ben,
I have been using a scraper to import Morningstar fund prices into Google sheets e.g.
=IMPORTXML(“http://www.morningstar.co.uk/uk/funds/snapshot/snapshot.aspx?id=F00000MC3M”, A2)
It was working fine but has recently started coming up with:
Error
Could not fetch url: http://www.morningstar.co.uk/uk/funds/snapshot/snapshot.aspx?id=F00000MC3M
However, I have found that if I change the ‘A2’ to ‘A3’ then back to ‘A2’ that the scraper starts working properly again, for a while.
Could you please tell me if there is there is anything that I can do to get the feed to continuosly update again?
Thanks.